1. resources -> templates -> application.yml생성
yml 또는 properties를 사용하면 된다.
설정파일이 복잡해지면 yml이 더낫다.
여기에서는 application.yml을 생성하고
기존에 있던 application.properties삭제 한다.
*YAML이란 (위키백과 참고)
- XML, C, 파이썬, 펄, RFC2822에서 정의된 e-mail 양식에서 개념을 얻어 만들어진
'사람이 쉽게 읽을 수 있는' 데이터 직렬화 양식
-XML과 JSON이 데이터 직렬화에 주로 쓰이기 시작하면서,
많은 사람들이 YAML을 '가벼운 마크업 언어'로 사용하려 함
*PROPERTIES이란 (위키백과 참고)
-응용 프로그램의 구성 가능한 파라미터들을 저장하기 위해
자바 관련 기술을 주로 사용하는 파일들을 위한 파일 확장자
-더 복잡한 설정 포맷을 원할 경우 XML와 YAML이 사용된다.
2. Database connection : 데이터베이스 소스 설정
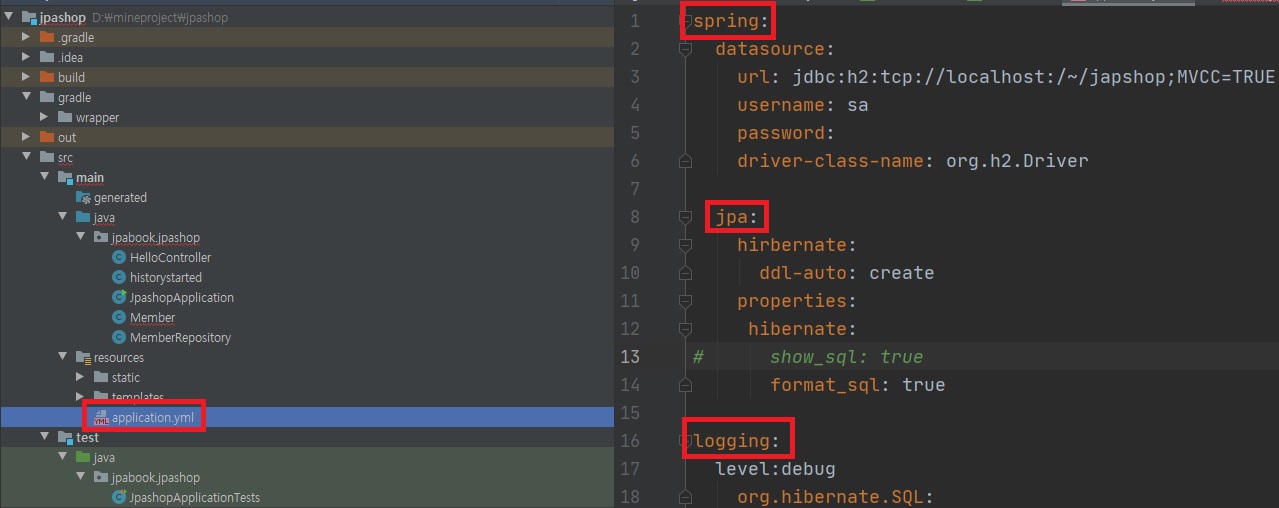
a. spring 세팅
datasource :
url: (상기사진내용참고)
username: sa
password:
driver-class-name: (상기사진내용참고)
(주의: 칸 띄어쓰기가 제대로 되어 맞춰지지 않는다면 테스트시 에러발생할 가능성이 크다!!)
설명
application.yml 안에
하기와 같이 설정하게 되면
데이터베이스 연결과 관련된 데이터소스설정이 완료 된다.
[url: jdbc:h2:tcp://localhost/~/jpashop;MVCC=TRUE]
*MVCC TRUE
-> 여러개가 접근할 때 조금 더 빨리 처리가 된다. 넣어주는 것이 권장.
*스프링부트에서 hikaricp를 써서 데이터베이스 커넥션 풀 등 위의 세팅이 이루어지게 한다.
b. JPA 세팅
hibernate:
ddl-auto: create
properties:
hibernate:
#show_sql: true
format_sql: true
*create은 tab을 자동생성해주는 역할을 한다.
application 실행시점에 내가가지고 있는 엔티티(테이블)정보를 전부 다 지우고,
다시 생성한다.
*properties (*hibernate와 관련된 특정한 properties 사용할 것을 여기에다가 타입한다.)
*설정하는 것을 어떻게 배우느냐
spring boot의 reference document를 참고해서 하나하나씩 공부해야 한다.
https://docs.spring.io/spring-boot/docs/2.2.6.RELEASE/reference/html/
Data Access ->configure JPA Properties를 찾아서 읽어볼 것!
c. LOG LEVEL세팅
logging:
level:
org.hibernate.SQL: debug
(주의 : 잘 안될 경우, logging.level:로 세팅할 것!)
*hibernate.SQL을 debug모드로 사용한다는 의미가 있고,
jpa나 hibernate가 생성하는 SQL전부 확인이 가능하다.
show_sql과 org.hibernate.SQL의 차이점
jpa:
show_sql: true
->system.out에 출력하는 것. 그래서 주석처리를 하여 사용하지 않도록 한다.
운영환경에서는 사용하지 않는다.
logging:
org.hibernate.SQL: debug
->log on을 통해 출력하는 것. 운영환경에서는 로그들을 log on을 통해 출력해야 한다.