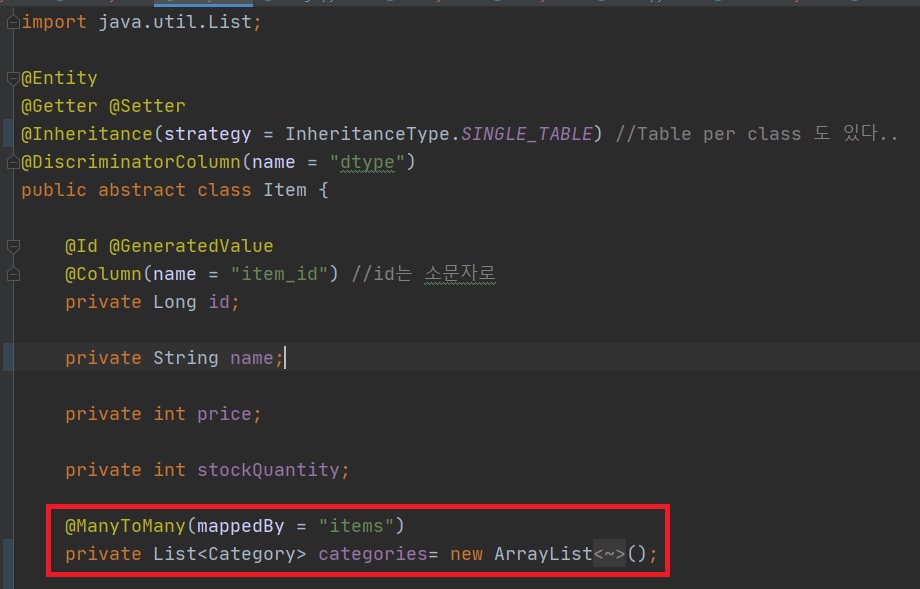
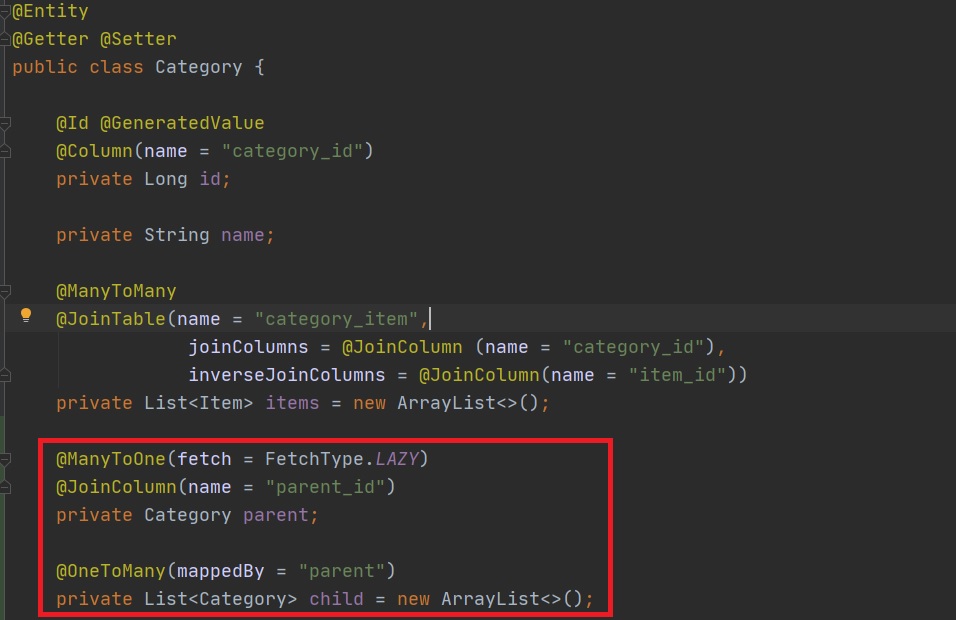
3.컬렉션은 필드에서 초기화 하자.
a.컬렉션은 필드에서 바로 초기화 하는 것이 안전하다.
예제사진
Best Practice
=>현재 만들어져 있는 것이 bestpractice이다.
이유
-우선은 초기화에 대해 고민할 필요가 없다.
-null문제에서 안전하다.(*null 개념 공부할 것)
설명
nulllpointerexeception이 생길일이 없다. 잘못되어서 체크할 일이 없다.
b.필드레벨에서 생성하는 것이 가장 안전하고, 코드도 간결하다.
-하이버네이트는 엔티티를 속화 할 때, 컬랙션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경한다.
getOrders()처럼 임의의 메서드에서 컬력션을 잘못 생성하면 하이버네이트 내부 메커니 즘에 문제가 발생할 수 있다.
설명예제1)
java
Member member = new Member();
System.out.println(member.getOrders().getClass());
em.persist(team);
System.out.println(member.getOrders().getClass());
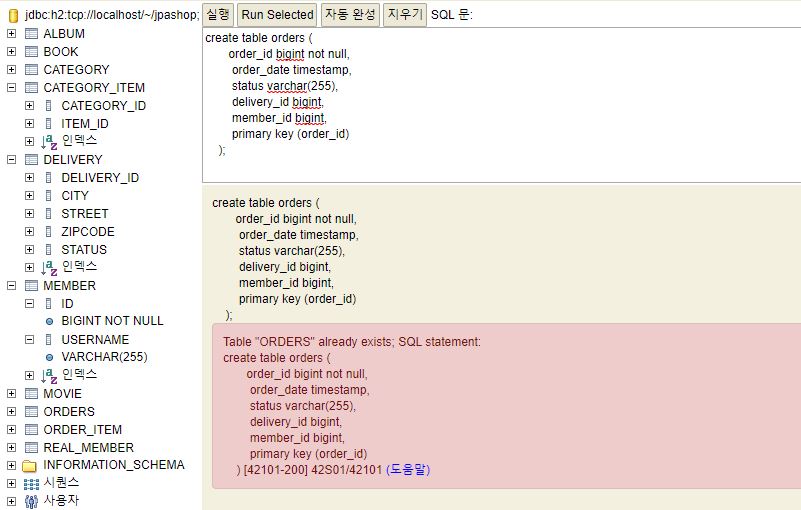
출력결과
class java,util.ArrayList //ArrayList가 나온다.
class org.hibernate.collection.internal.PersistentBag
설명
java
Member member = new Member(); //멤버객체 생성
System.out.println(member.getOrders().getClass());
출력결과 -> class java,util.ArrayList //ArrayList가 나온다.
java
Member member = new Member();
System.out.println(member.getOrders().getClass());
위의 구문 출력후 다시 밑에서부터 이어서 작성
em.persist(team);
출력결과->class org.hibernate.collection.internal.PersistentBag
em.persist(team); 설명
-persist로 영속을 한다라는 의미
-위의 코드 작성후, jpa입장에서는 db에 저장하겠다라고 선언 하고,
-영속성컨텍스트(컬렉션 : Orders)관리를 해주어야 한다.
-그다음에 다시 하기와 같이 작성해준다.
설명(출력결과->class org.hibernate.collection.internal.PersistentBag)
-기존 것을 가지고 감싸버린다. 하이버네이트가 컬렉션이 바뀌어버리면 추적을 해야 하므로,
본인이 추적할 수 있는 형태/내장컬렉션(타입에 따라 다름, PersistentBag)로 바꾸어 버린다.
문제는, 하이버네이트가 바꾸어 놓은 형태인상태에서 다시 누군가 컬렉션(Orders)부분을
set으로 바꾸어 버린다면 하이버네이트가 원하는 메카니즘으로 돌아오지 않는다.
그래서 어떻게 해야 하냐면, 현재 위에 사진에서 작성한 대로 필드레벨에서 생성을 한다.
-컬렉션을 변경하지 말아야 한다. 객체생성할때의 그대로 사용하길 권유한다.
-하이버네이트가 관리하는 컬렉션으로 바뀌었고, 변경할 경우 하이버네이트가 원하는 메카니즘대로 동작을 안한다.
*하이버네이트가 엔티티를 펄시스트 하는 순간 컬렉터를 감싸거나 안에서 무슨일이 일어나면서,
하이버네이트가 제공하는 내장 컬렉션으로 변경이 된다.
-따라서 필드레벨에서 생성하는 것이 가장 안전하고, 코드도 간결하다.
=>컬렉션을 필드에서 바로 초기화 해라!!!
4. 테이블 컬럼명 생성 전략
-스프링 부트에서 하이버네이트 기본 매핑 전략을 변경해서 실제 테이블 필드명은 다름
설명
-하기와 같이 @Table(name = “user“)로 설정을 하면 테이블명이 user로 바뀐다.
예제)
@Entity
@Table(name = "user")
@Getter @Setter
public class Member {
.....
}
만약 위의 @Table을 사용하지 않으면 테이블명이 어떻게 되나요?
1.하이버네이트 기존 기본매핑전략 구현
-엔티티의 필드명을 그대로 테이블 명으로 사용
(SpringPhysicalNamingStrategy)
예)private LocalDateTime orderDate;
테이블명 -> orderdate 그대로 사용
2.스프링 부트 신규 기본매핑전략 구현 설정 (엔티티(필드) 테이블(컬럼))
a. 카멜 케이스 언더스코어(memberPoint -> member_point)
예)private LocalDateTime orderDate;
테이블명 -> order_date 로 변경
b. .(점) _(언더스코어)
예)
c. 대문자 소문자
예)
*테이블명 설정되는 로직 내용 확인
메뉴상단바 -> Navigate -> SearchEverywhere -> Class->
SpringPhysicalNamingStrategy 입력
적용 2단계 (공부필요)
1. 논리명 생성
-테이블명을 직접 적지 않으면 ImplicitNamingStrategy 사용하게 된다.
*spring.jpa.hibernate.naming.implicit-strategy
-테이블이나, 컬럼명을 명시하지 않을 때 논리명 적용
스프링부트 기본설정
spring.jpa.hibernate.naming.implicit-strategy:
org.springframework.boot.orm.jpa.hibernate.SpringImplicitNamingStrategy
2. 물리명 적용
-spring.jpa.hibernate.naming.physical-strategy
-테이블이나 컬럼명의 채워져 있든 아니든 논리명 모두에게 적용이 된다. 즉, 실제 테이블에 적용하게 된다.
(username usernm 등으로 회사 룰로 바꿀 수 있음)
스프링부트 기본설정
spring.jpa.hibernate.naming.physical-strategy:
org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
'신입개발자로 취업하기까지 > JPA쇼핑몰기능구축' 카테고리의 다른 글
| 20200525 클래스파일 이름변경후 데이터베이스 연동(문제해결) (0) | 2020.06.22 |
|---|---|
| 20200525 엔티티설계 보충설명 (0) | 2020.06.08 |
| 20200523 엔티티설계 및 개발시 주의점_1 (0) | 2020.06.08 |
| 20200519 도메인분석설계_엔티티클래스 개발 1-6 (0) | 2020.06.07 |
| 20200518 도메인분석설계_엔티티클래스 개발 1-5 (0) | 2020.06.07 |